building intuition for recurrent neural network
So one of the most difficult topics to understand is Recurrent Neural networks and LSTMs. When I jumped from traditional neural networks to recurrent neural networks to recurrent networks for the first time I could not build intuition about it. Scraping internet finding blog posts and videos reading as much I can and do not get inside feeling that I got it Ya!. Then I tried to follow Richard Feynman’s approach of learning to learn it and this blog post is the result of it. As I was reviewing my notes I found this topic and I thought the better place for this is in a blog instead of my rough and bad writing and decided to make it live.


When we are in school why don’t we get to sit in highschool directly if it’s the first exam that matter’s lot?
Why do we have to study class (grade) first to ninth before sitting in highschool?

These questions are base on human intelligence persistence of knowledge and this is the base of Recurrent Neural Networks. Humans do not learn everything from scratch every time. We have saved memory which helps us to learn new things later based on previous experience. Human intelligence has persistence.
Let us now consider a machine learning example. We feed an essay about a topic to model and it learns about that topic such that now if we ask any questions about that topic we get the result. Basically example of a text summarizer. The same manner as our teacher teaches us and in exam asks questions based on what they teach and we write answers based on what we have learned previously.
Traditional Neural Networks cannot do this and it seems like a major shortcoming. Imagine it yourself how traditional neural network and be used to output based on previous input.
Recurrent Networks comes to rescue here and are helpful if data is sequential or our output depends on previous events or learnings.
Simple Recurrent Networks also have some cons like gradient vanishing problem and gradient exploding problem but we will deal it with later.
Structure
These are the same as traditional neural networks but the only difference is we have them in sequence with the output of one neural network to input of other ie.. each network passes its state or learnings to its successor.
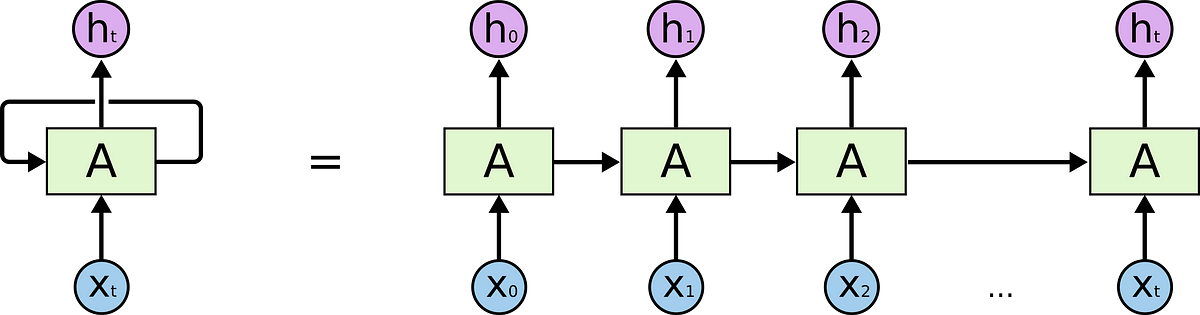
This chain-like structure of sequence can help us to build intuition about why recurrent networks are used in sequential data.

Box A in the above diagram I denote it as the state of the network because it is representing learnings of the network which are basically optimized values of weight and biases.
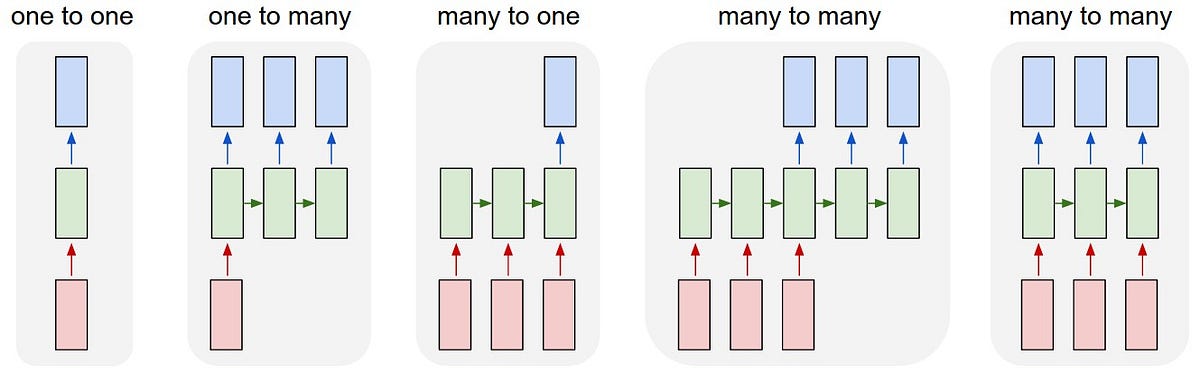
Different models of RNN
- ONE TO MANY
One input many outputs. Example: Image Captioning (one image is given and we get a sequence of words describing the image.)
- MANY TO ONE
Many inputs (sequence of data) -> One output. Example: Sentimental Analysis
- ONE TO ONE
Fixed Size input to fixed-size output. Example: Image Classification
- MANY TO MANY
(sequence of input) -> (sequence of output). Example: Language Translation
Working
The working of the recurrent neural net is same as traditional neural networks each network has set of weight and biases as parameters and we optimize them by means of gradient descent or its variants but the difference is now we also have extra sets of vectors for weight and biases which will be passed to every network in sequence or chain which are learnings of the network in the previous stage. That’s why we have a looping arrow in the state of the network because we are looping through these extra hyperparameters in every sequence of the network. Every prediction at time t is depending on its previous results. Unlike traditional neural network where all inputs are independent of one other. We calculate hidden layer values not only from input values but also from previous timestep values.
(State) S=activation(Wl * Xt + W * St-1)
where S=Current State or learning, Wl=Weights of the layer we are on, Xt= Current input, St-1= Previous State or learning, activation= any activation function (sigmoid, relu, tanh etc)
So I hope it helps someone to make intuition of the recurrent neural network.